


En Buffer, hemos estado trabajando en un mejor panel de suministro para nuestro equipo de defensa del cliente. Este panel de suministro incluía una funcionalidad de búsqueda mucho más poderosa. A medida que se acerca el final del cronograma del esquema, se nos ha pedido que reemplacemos Elasticsearch administrado en AWS con Opensearch administrado. Nuestro esquema se basó en versiones más nuevas del cliente elasticsearch que de repente no era compatible con Opensearch.
Para añadir combustible al fuego, los clientes de OpenSearch para los idiomas que usamos aún no admitían firmas AWS Sigv4 transparentes. La firma de AWS Sigv4 es un requisito para autenticarse en el clúster de OpenSearch con las credenciales de AWS.
Eso significaba que el camino a seguir estaba plagado de una de estas opciones.
- Deje nuestro orden de búsqueda rajado al mundo sin autenticación, funcionaría con el cliente OpenSearch. No hace desatiendo asegurar que este es un gran NO PUEDE por razones obvias.
- Refactorice nuestro código para mandar solicitudes HTTP sin procesar e implemente el mecanismo AWS Sigv4 en estas solicitudes nosotros mismos. ¡Esto es inasequible, y no nos gustaría reinventar una biblioteca de cliente nosotros mismos!
- Cree un complemento/middleware para el cliente que implemente la firma de AWS Sigv4. Funcionaría al principio, pero Buffer no es un gran equipo y con actualizaciones de servicio constantes, no es poco que podamos surtir de guisa confiable.
- Cambia nuestra infraestructura para usar un clúster de búsqueda elástica alojado en la nimbo de Elastic. Requirió un tremendo esfuerzo cuando analizamos los términos de uso, los precios, los requisitos para la configuración segura de la red y otras medidas de Elastic.
¡Parecía que este esquema estaba atascado a grande plazo! ¿Donde estaba?
Mirando la situación, aquí están las constantes que no podemos cambiar de guisa realista.
- Ya no podemos usar el cliente de elasticsearch.
- Cambiar al cliente de OpenSearch funcionaría si el clúster estuviera rajado y no requiriera ninguna autenticación.
- No podemos dejar el clúster de OpenSearch rajado al mundo por razones obvias.
¿No sería bueno si el clúster de OpenSearch estuviera rajado SOLO para las aplicaciones que lo necesitan?
Si esto se puede conseguir, entonces estas aplicaciones podrían conectarse al clúster sin autenticación que les permita usar el cliente OpenSearch existente, pero de lo contrario, el clúster sería inaccesible.
Con este objetivo final en mente, hemos diseñado la sucesivo alternativa.
Sobre la cojín de nuestra fresco migración de Kubernetes autogestionado a Amazon EKS
Recientemente migramos nuestra infraestructura informática de un clúster de Kubernetes autoadministrado a otro clúster administrado por Amazon EKS.
Con esta migración, cambiamos nuestra interfaz de red de contenedores (CNI) de franela a VPC CNI. Esto implica que hemos eliminado la división de redes superpuestas/subyacentes y todos nuestros pods ahora obtienen direcciones IP enrutables de VPC.
Esto será más relevante en el futuro.
Encerrar el entrada al clúster desde el mundo foráneo
Creamos un clúster de OpenSearch en una VPC privada (sin direcciones IP orientadas a Internet). Esto significa que las direcciones IP del clúster no serían accesibles a través de Internet, solo las direcciones IP enrutables de la VPC interna.
Agregamos tres grupos de seguridad al clúster para controlar qué direcciones IP de VPC pueden ganar al clúster.
Cree automatizaciones para controlar lo que puede entrar al clúster
Construimos dos automatizaciones que funcionan como AWS lambdas.
- Administrador de orden de seguridad: esta automatización puede ejecutar dos procesos bajo demanda.
- -> Agregue una dirección IP a uno de estos tres grupos de seguridad (el que tiene menos reglas en el momento de la complemento).
- -> Elimine una dirección IP dondequiera que aparezca en estos tres grupos de seguridad.
- Auditor del ciclo de vida del pod: esta automatización se está ejecutando según lo programado y veremos qué hace en un momento.
Hemos ayudante un InitContainer a todos los pods que requieren entrada al clúster de OpenSearch que, al iniciarse, ejecutará la automatización del administrador del orden de seguridad y le pedirá que agregue la dirección IP del pod a uno de los grupos de seguridad. Esto le permite ganar al clúster de OpenSearch.
En la vida vivo suceden cosas y los pods mueren y obtienen nuevas direcciones IP. Por lo tanto, a tiempo, Pod Lifecycle Auditor ejecuta y verifica todas las direcciones IP incluidas en la repertorio blanca en los tres grupos de seguridad que permiten el entrada al clúster. Luego verifica qué direcciones IP no deberían estar allí y reconcilia los grupos de seguridad pidiéndole al administrador del orden de seguridad que elimine estas direcciones IP.
Aquí hay un diagrama de cómo se conecta todo.
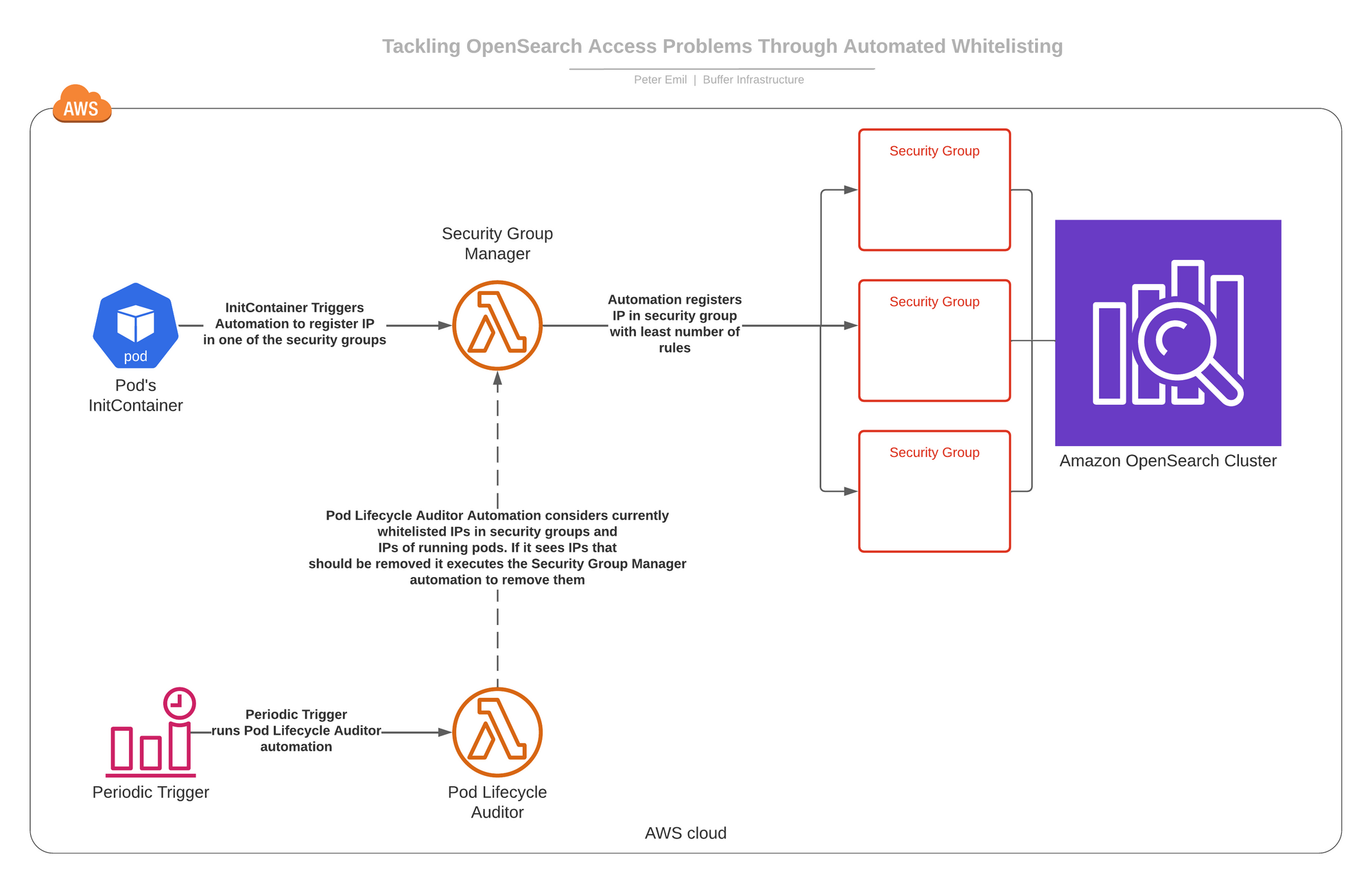
¿Por qué creamos tres grupos de seguridad para dirigir el entrada al clúster de OpenSearch?
Porque los grupos de seguridad tienen un término mayor de 50 reglas de E/S. Anticipamos que no tendremos más de 70-90 pods en un momento transmitido que necesiten entrada al clúster. Tener tres grupos de seguridad establece el término en 150 reglas, que creemos que es un área seguro para comenzar.
¿Debo encajar el clúster de Opensearch en la misma VPC que el clúster de EKS?
¡Depende de la configuración de su red! Si su VPC tiene subredes privadas con puertas de enlace NAT, puede alojarla en cualquier VPC que elija. Si no tiene subredes privadas, debe hospedar uno y otro clústeres en la misma VPC, ya que la CNI de la VPC hace que el NAT predeterminado del tráfico del módulo extranjero de la VPC se envíe a la dirección IP del nodo de hospedaje, lo que invalida esta alternativa. Si deshabilita la configuración de NAT, sus pods no pueden entrar a Internet, lo cual es un problema anciano.
Si un pod se atasca en el estado CrashLoopBackoff, ¿el gran grosor de reinicios no agotará el término de 150 reglas?
No, porque los bloqueos de contenedores en un pod se reinician con la misma dirección IP en el mismo pod. La dirección IP no se cambia.
¿No son estas automatizaciones un único punto de error?
Sí, por eso es importante abordarlos con una mentalidad SRE. El monitoreo adecuado de estas automatizaciones combinado con implementaciones graduales es crucial para tener confiabilidad aquí. Desde que se implementaron estas automatizaciones han sido muy estables y no hemos tenido incidencias. Sin secuestro, duermo profundamente por la sombra sabiendo que si alguno de ellos se rompe por algún motivo, se me notificará mucho ayer de que se convierta en un problema sobresaliente.
Reconozco que esta alternativa no es perfecta, pero fue la alternativa más rápida y ligera de implementar sin exigencia de mantenimiento continuo y sin sumergirse en el proceso de incorporación de un nuevo proveedor de nimbo.
A usted
¿Qué opinas del enfoque que hemos tomado aquí? ¿Te has opuesto con situaciones similares en tu estructura? ¡Tuiteanos!